YOLO Algorithm and YOLO Object Detection


Image classification is one of the many exciting applications of convolutional neural networks. Aside from simple image classification, there are plenty of fascinating problems in computer vision, with object detection being one of the most interesting. YOLO (“You Only Look Once”) is an effective real-time object recognition algorithm, first described in the seminal 2015 paper by Joseph Redmon et al. In this article, we introduce the concept of object detection, the YOLO algorithm itself, and one of the algorithm's open-source implementations: Darknet. If you're ready to live life to the fullest and Carpe Imaginem, continue reading. We promise to minimize our use of outdated slang terms. Updated: March 17, 2022.
- Object Detection Overview
- Understanding YOLO Object Detection: The YOLO Algorithm
- YOLO Variants - Everything You Need to Know
- Darknet: A YOLO Implementation
Object detection overview
Object detection is commonly associated with self-driving cars where systems blend computer vision, LIDAR, and other technologies to generate a multidimensional representation of the road with all its participants. It is also widely used in video surveillance, especially in crowd monitoring to prevent terrorist attacks, count people for general statistics or analyze customer experience with walking paths within shopping centers.How does object detection work
To explore the concept of object detection it's useful to begin with image classification. Image classification goes through levels of incremental complexity.- Image classificationaims at assigning an image to one of a number of different categories (e.g. car, dog, cat, human, etc.), essentially answering the question “What is in this picture?”. One image has only one category assigned to it.
- Object localizationallows us to locate our object in the image, so our question changes to “What is it and where it is?”.
- Object detectionprovides the tools for doing just that – finding all the objects in an image and drawing the so-called bounding boxes around them.
 Instance segmentation process
Instance segmentation process
Object detection algorithms
There are a few different algorithms for object detection and they can be split into two groups.Algorithms based on classification
They are implemented in two stages:- They select regions of interest in an image.
- They classify these regions using convolutional neural networks.
Algorithms based on regression
Instead of selecting interesting parts of an image, they predict classes and bounding boxes for the whole image in one run of the algorithm. The two best-known examples from this group are the YOLO (You Only Look Once) family algorithms and SSD (Single Shot Multibox Detector). They are commonly used for real-time object detection as, in general, they trade a bit of accuracy for large improvements in speed.Understanding YOLO object detection: the YOLO algorithm
To understand the YOLO algorithm, it is necessary to establish what is actually being predicted. Ultimately, we aim to predict a class of an object and the bounding box specifying object location. Each bounding box can be described using four descriptors:- center of a bounding box (bxby)
- width (bw)
- height (bh)
- value cis corresponding to a class of an object (e.g., car, traffic lights, etc.)
To learn more about PP-YOLO (or PaddlePaddle YOLO), which is an improvement on YOLOv4, read our explanation of why PP-YOLO is faster than YOLOv4.In addition, we have to predict the pc value, which is the probability that there is an object in the bounding box.
 Bounding box probability calculation
As we mentioned above, when working with the YOLO algorithm we are not searching for interesting regions in our image that could potentially contain an object.
Instead, we are splitting our image into cells, typically using a 19x19 grid. Each cell is responsible for predicting 5 bounding boxes (in case there is more than one object in this cell). Therefore, we arrive at a large number of 1805 bounding boxes for one image. Rather than seizing the day with #YOLO and Carpe Diem, we're looking to seize object probability. The exchange of accuracy for more speed isn't reckless behavior, but a necessary requirement for faster real-time object detection.
Bounding box probability calculation
As we mentioned above, when working with the YOLO algorithm we are not searching for interesting regions in our image that could potentially contain an object.
Instead, we are splitting our image into cells, typically using a 19x19 grid. Each cell is responsible for predicting 5 bounding boxes (in case there is more than one object in this cell). Therefore, we arrive at a large number of 1805 bounding boxes for one image. Rather than seizing the day with #YOLO and Carpe Diem, we're looking to seize object probability. The exchange of accuracy for more speed isn't reckless behavior, but a necessary requirement for faster real-time object detection.
 Image size-reduction
Most of these cells and bounding boxes will not contain an object. Therefore, we predict the value pc, which serves to remove boxes with low object probability and bounding boxes with the highest shared area in a process called non-max suppression.
Image size-reduction
Most of these cells and bounding boxes will not contain an object. Therefore, we predict the value pc, which serves to remove boxes with low object probability and bounding boxes with the highest shared area in a process called non-max suppression.
 Non-max suppression
Non-max suppression
YOLO Variants - Everything You Need to Know
By now you have a good idea of what the YOLO algorithm represents. If you want to learn more, you're in luck. We'll now go over 11 different algorithm variations released over the years, and then make a brief summary to find out which is the best and the most recent flavor.YOLOv1
The first YOLO version was announced in 2015 by Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi in the article “You Only Look Once: Unified, Real-Time Object Detection”. Not long after, YOLO dominated the object-detection field and became the most popular algorithm used, because of its speed, accuracy, and learning ability. Instead of treating object detection as a classification problem, the authors thought about it as a regression task concerning spatially separated bounding boxes and associated class probabilities, using a single neural network. The YOLOv1 processed images in real-time at 45 frames per second, while a smaller version - Fast YOLO - reached 155 frames per second and still achieved double the mAP of other real-time detectors. YOLOV1 algorithm scheme
YOLOV1 algorithm scheme
YOLOv2
YOLOv2 (sometimes called YOLO9000), was released a year later, in 2016 also by Joseph Redmon and Ali Farhadi in the article “YOLO9000: Better, Faster, Stronger”. The name with number 9000 was given, because of the model's ability to predict even 9000 different objects categories and still run in real-time. The novel model version was not only trained simultaneously on object detection and classification datasets but also gained Darknet-19 as the new baseline model. Since YOLOv2 was also a huge success and became the next state-of-the-art object detection model, more and more engineers began to experiment with this algorithm and create their own, diverse YOLO versions. Some of them will be mentioned throughout the article.YOLOv3
The new version of the algorithm was released in 2018 by Joseph Redmon and Ali Farhadi in the article "YOLOv3: An Incremental Improvement". It was based on the Darknet-53 architecture. In YOLOv3, the softmax activation function was replaced with independent logistic classifiers. During training, the binary cross-entropy loss was used. The Darknet-19 architecture was improved and changed into Darknet-53, with 53 convolutional layers. Besides that, the predictions were made on three different scales that improved YOLOv3’s AP in predicting small objects. Darknet53 architecture
YOLOv3 was the last YOLO variant created by Joseph Redmon, who decided to never work on any upgrades of YOLO (or even in the computer vision field), in order to prevent his work’s negative impact on the world. Nowadays, it is mostly used as the baseline for developing novel object-detection architectures.
Darknet53 architecture
YOLOv3 was the last YOLO variant created by Joseph Redmon, who decided to never work on any upgrades of YOLO (or even in the computer vision field), in order to prevent his work’s negative impact on the world. Nowadays, it is mostly used as the baseline for developing novel object-detection architectures.
 YOLOv3 performance
YOLOv3 performance
YOLOv4
The fourth version of the YOLO algorithm was released in April 2020 by Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan Mark Liao in their article "YOLOv4: Optimal Speed and Accuracy of Object Detection". It was based on the SPDarknet53 architecture and introduced a fair amount of new concepts, such as Weighted Residual Connections, Cross-Stage-Partial connections, cross mini-batch normalization, self-adversarial training, mish activation, dropblock, and CIoU loss. YOLOv4 is the continuation of the YOLO family but was created by different scientists (not Joseph Redmon and Ali Farhadi). Its architecture consists of SPDarknet53 backbone, spatial pyramid pooling, PANet path-aggregation as neck, and YOLOv3 head. As a result, YOLOv4 reaches 10% higher Average Precision and 12% better Frames Per Second metrics, compared to its ancestor, YOLOv3.YOLOv5
The fifth iteration of the most popular object detection algorithm was released shortly after YOLOv4, but this time by Glenn Jocher. First time ever, YOLO used the PyTorch deep learning framework, which aroused a lot of controversy among the users. The official article couldn’t be announced, because YOLOv5 does not implement or invent any novel techniques. It is just the PyTorch extension of YOLOv3. Such a situation was used by Ultranytics company and spread the word about the “new YOLO” version under its patronage. The fact is, that the YOLOv5 webpage is very clear and nicely built and written, with a lot of tutorials and tips on training and using the YOLOv5 models because there are also five pre-trained models available, ready for use. YOLOv5 subversions
Due to some researchers, YOLOv5 outperforms both YOLOv4 and YOLOv3, but its speed is similar to YOLOv4.
YOLOv5 subversions
Due to some researchers, YOLOv5 outperforms both YOLOv4 and YOLOv3, but its speed is similar to YOLOv4.
 YOLOv5 performance
YOLOv5 performance
PP-YOLOv1 and v2
The PP-YOLO algorithm was released in July 2022 by Xiang Long et al. and Baidu team in the articles "PP-YOLO: An Effective and Efficient Implementation of Object Detector" and "PP-YOLOv2: A Practical Object Detector". It uses the ResNet50-vd architecture as a backbone and introduces many new features, such as larger batch size, EMA, dropblock, IoU loss, IoU aware, grid sensitive, matrix NMS, CoordConv, and Spatial Pyramid Pooling. PP-YOLO’s name “PP” means “Paddle-Paddle” (Parallel Distributed Deep Learning), which is an open-source deep learning platform, also developed by the Baidu team and used for this project’s needs. They used YOLOv3 as the baseline model and incorporated some tricks, in order to obtain a better balance between effectiveness and efficiency, surpassing, for example, YOLOv4. The original backbone was replaced (DarkNet-53) with ResNet50-vd. The construction of FPN and head are the same as in YOLOv3 architecture. The latest version, with even more improvements, but mostly focused on performance, than speed, PP-YOLOv2, again authored by the Baidu team, was released in April 2021. PP-YOLO performance
PP-YOLO performance
YOLOP (You Only Look Once for Panoptic Driving Perception)
The YOLOP version was released in August 2021 by Xinggang Wang et al. in their article "YOLOP: You Only Look Once for Panoptic Driving Perception". It uses CSPDarknet architecture as a backbone and packs a ton of new features, including panoptic driving system, 1 encoder and 3 decoders for traffic object detection, lane detection, and drivable area segmentation. It was completely different from other YOLO versions announced in the same year. YOLOP is tailored especially for panoptic driving tasks, not for a wide object-detection. It is the real-time perception system, well-tested in real situations, ready to assist a car in making reasonable decisions while driving. YOLOP is composed of one shared encoder for feature extraction and three decoders to handle the specific tasks - traffic object detection, lane detection and drivable area segmentation at the same time. As usual, the encoder consists of the backbone part, which extracts the features of the input image and the neck part, which merges features generated by the backbone. The backbone network is based on architecture similar to YOLOv4 - CSPDarknet, while the neck is composed of Spatial Pyramid Pooling (SPP) module and Feature Pyramid Network (FPN) module. The three decoders (Detect Head, Drivable Area Segment Head and Lane Line Segment Head) have a similar architecture to those in YOLOv4, only Drivable Area Segment Head and Lane Line Segment Head have, in the upsampling layer, the nearest interpolation, instead of deconvolution, in order to reduce computation cost. Nearest neighbor interpolation scheme
YOLOP achieves state-of-the-art on the three tasks of the BDD100K dataset in terms of accuracy and speed. It was the first model to perform the three panoptic perception tasks simultaneously in real-time on an embedded device (Jetson TX2) and achieves state-of-the-art performance.
Nearest neighbor interpolation scheme
YOLOP achieves state-of-the-art on the three tasks of the BDD100K dataset in terms of accuracy and speed. It was the first model to perform the three panoptic perception tasks simultaneously in real-time on an embedded device (Jetson TX2) and achieves state-of-the-art performance.
 YOLOP architecture
YOLOP architecture
YOLOX
Another YOLO flavor - YOLOX - was released in August 2021 by Jian Sun et al. in their article "YOLOX: Exceeding YOLO Series in 2021". It was based on the DarkNet53 architecture and SPP layer. Like other flavors, YOLOX also came with a bunch of characteristic features, such as anchor-free mechanism, decoupled head, SimOTA, EMA weights updating, cosine lr schedule, IoU loss, and IoU-aware branch. The authors used YOLOv3 architecture (Darknet53 with SPP layer) as the starting point for developing a novel model. The experiments indicated that the coupled detection head may have a negative impact on the performance and replacing the head with a decoupled one greatly improved the converging speed. The decoupled head consists of a 1×1 convolution layer that reduces the channel dimension and two parallel branches with two 3×3 convolutional layers. YOLOv3 head vs. the proposed decoupled head
YOLOX uniqueness results from the decision to drop the construct of box anchors, which improves the computation cost and inference speed. In an anchor-free mechanism, the predictions for each location are reduced from 3 to 1 and directly predict four values (two offsets in terms of the left-top corner of the grid, and the height and width of the predicted box).
Then, the center location of every object is assigned as the positive one (only one for each object, ignoring other high-quality predictions), and a scale range pre-defined. These changes reduced the parameters and GFLOPs of the detector and obtained better performance in AP.
Besides that, the authors present a novel SimOTA, an advanced label assignment technique, which treats the assigning procedure as an Optimal Transport (OT) problem and gets state-of-the-art performance among the assigning strategies.
YOLOX won the 1st Place in Streaming Perception Challenge (Workshop on Autonomous Driving at CVPR 2021) using a single YOLOX-L model.
YOLOv3 head vs. the proposed decoupled head
YOLOX uniqueness results from the decision to drop the construct of box anchors, which improves the computation cost and inference speed. In an anchor-free mechanism, the predictions for each location are reduced from 3 to 1 and directly predict four values (two offsets in terms of the left-top corner of the grid, and the height and width of the predicted box).
Then, the center location of every object is assigned as the positive one (only one for each object, ignoring other high-quality predictions), and a scale range pre-defined. These changes reduced the parameters and GFLOPs of the detector and obtained better performance in AP.
Besides that, the authors present a novel SimOTA, an advanced label assignment technique, which treats the assigning procedure as an Optimal Transport (OT) problem and gets state-of-the-art performance among the assigning strategies.
YOLOX won the 1st Place in Streaming Perception Challenge (Workshop on Autonomous Driving at CVPR 2021) using a single YOLOX-L model.
YOLOF (You Only Look One-level Feature)
The YOLOF model was released in March 2021 by Jian Sun’s team in their article "You Only Look One-level Feature". Their flavor used ResNet/ResNeXt architectures pre-trained on the ImageNet dataset. It came with a couple of new features, such as single-level features, Dilated Encoder, and Uniform Matching. This time, the authors focused on adopting SiSo (single-in, single-out) encoders, instead of complex feature pyramids for detection, in order to lower the computational cost. Such a task turned out to have two main problems:- The detection performance of SiSo drops due to the range of scales (of objects in the picture) that such features can cover, they are more limited than MiMo
- Imbalance problem with positive anchors connected with sparse anchors in single-level features
 MiMo vs. SiMo vs. MiSo vs. SiSo encoders
Two novel components in this YOLOF architecture are Dilated Encoder and Uniform Matching, which solve the above problems and bring considerable improvements in performance.
Dilated Encoder consists of the Projector (1x1 convolution layer to reduce dimension, then one 3x3 convolution layer to improve semantic contexts) and the Residual Blocks (four blocks with different dilation rates, to generate output features with multiple receptive fields, covering all objects’ scales).
MiMo vs. SiMo vs. MiSo vs. SiSo encoders
Two novel components in this YOLOF architecture are Dilated Encoder and Uniform Matching, which solve the above problems and bring considerable improvements in performance.
Dilated Encoder consists of the Projector (1x1 convolution layer to reduce dimension, then one 3x3 convolution layer to improve semantic contexts) and the Residual Blocks (four blocks with different dilation rates, to generate output features with multiple receptive fields, covering all objects’ scales).
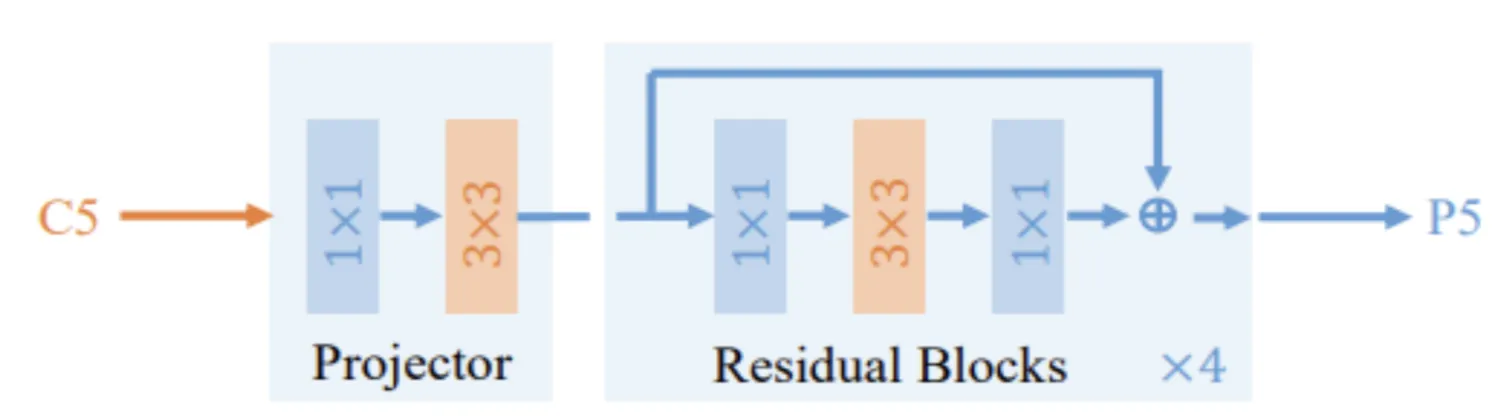 Structure of a Dilated Encoder
Uniform Matching is used to take care of the sparse anchors' problem. First, the k nearest anchors are set as positive ones, for every ground-truth box, so that all ground-truth boxes have the same number of positive anchors regardless of their sizes. Balance in positive samples makes sure that all ground-truth boxes participate in training and contribute equally.
Thanks to these changes, YOLOF is able to achieve comparable results with its feature pyramids rival - RetinaNet, while being 2.5x faster. YOLOF-DC5 can be 13% faster than YOLOv4 with a 0.8 mAP improvement in overall performance.
Structure of a Dilated Encoder
Uniform Matching is used to take care of the sparse anchors' problem. First, the k nearest anchors are set as positive ones, for every ground-truth box, so that all ground-truth boxes have the same number of positive anchors regardless of their sizes. Balance in positive samples makes sure that all ground-truth boxes participate in training and contribute equally.
Thanks to these changes, YOLOF is able to achieve comparable results with its feature pyramids rival - RetinaNet, while being 2.5x faster. YOLOF-DC5 can be 13% faster than YOLOv4 with a 0.8 mAP improvement in overall performance.
 YOLOF architecture
YOLOF architecture
YOLOS (You Only Look at One Sequence)
A transformed-based YOLO version - YOLOS - was released in October 2021 by Wenyu Liu et al. in their paper "You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection". It was built on an entirely different architecture and brought to light new features, such as ViT transformers and DET tokens. The authors emphasize that YOLOS is, at this moment, a proof-of-concept with no performance optimizations, its purpose was to prove the Transformers' versatility and transferability to the more challenging object detection task, than just image recognition. YOLOS consists of a series of object detection models based on the ViT architecture with the fewest possible modifications and inductive biases. For the pre-training dataset was used the mid-sized ImageNet-1, and the vanilla ViT architecture, with the fewest possible modifications. For the first time, the 2D object detection was performed in a pure sequence-to-sequence manner by taking a sequence of fixed-sized non-overlapping image patches. One of the important changes was adopting [DET] tokens as proxies for object representations to avoid inductive biases about 2D structures and prior knowledge about the task. Besides that, image classification loss in ViT is replaced with the bipartite matching loss to perform object detection in a set prediction manner. YOLOS architecture
A small variant of YOLOS (YOLOS-Ti) was able to achieve impressive performance compared to the highly-optimized object detectors; unfortunately, the larger YOLOS models were less competitive.
YOLOS architecture
A small variant of YOLOS (YOLOS-Ti) was able to achieve impressive performance compared to the highly-optimized object detectors; unfortunately, the larger YOLOS models were less competitive.
 Self-attention map visualization
Self-attention map visualization
YOLOR (You Only Learn One Representation)
The final YOLO flavor we'll take a look at today is YOLOR, and it was released in May 2021 by Hong-Yuan M. Liao et al. in their article "You Only Learn One Representation: Unified Network for Multiple Tasks". It introduced two distinctive features - implicit and explicit knowledge. The authors decided to use a completely novel approach and introduce both implicit and explicit knowledge into the neural network that is responsible for object-detection tasks, in order to improve its performance. The unified neural network integrates implicit knowledge and explicit knowledge and enables the learned model to contain a general representation that can complete various tasks. To train such a unified network, the explicit and implicit knowledge were incorporated together to model the error term and then used to guide the multi-purpose network training process. As the baseline model YOLOv4- CSP was taken. The implicit knowledge was applied in three places:- Feature alignment for FPN
- Prediction refinement
- Multi-task learning in a single model (tasks included: object detection, multi-label image classification, and feature embedding)
 YOLOR architecture
YOLOR reached similar accuracy as Scaled-YOLOv4-P7 on object detection, but the inference speed increased by 88%:
YOLOR architecture
YOLOR reached similar accuracy as Scaled-YOLOv4-P7 on object detection, but the inference speed increased by 88%:
 YOLOR performance
YOLOR performance
YOLO Models Summary
Out of the five models released in 2021 (YOLOP, YOLOX, YOLOF, YOLOS, YOLOR), only YOLOR and YOLOX are in the top 10 models of the COCO benchmark. The first place, based on box AP, belongs to YOLOR, the second still to YOLOv4, and the third to PP-YOLO. YOLOF slightly misses the top ten places. YOLOS models are proofs of concept, which at this moment, can’t compete with the state-of-the-art methods. Meanwhile, the YOLOP model is based on a completely different concept of the panoptic perception system and can’t be compared with more general object detection models. YOLOs performance comparison on COCO dataset
YOLOs performance comparison on COCO dataset
Darknet: a YOLO implementation
There are a few different implementations of the YOLO algorithm on the web. Darknet is one such open-source neural network framework. Darknet was written in the C Language and CUDAtechnology, which makes it really fast and provides for making computations on a GPU, which is essential for real-time predictions. If you're curious about other examples of the YOLO algorithm in action, you can take a look at a PyTorch implementation or check out YOLOv3 with some extra fast.ai functionality. For a complete overview, explore the Keras implementation. Darknet logo
Installation is simple and requires running just 3 lines of code (in order to use GPU it is necessary to modify the settings in the Makefile script after cloning the repository). For more details, see the Darknet installation instructions.
After installation, we can use a pre-trained model or build a new one from scratch. For example, here’s how you can detect objects on your image using a model pre-trained on the COCO dataset:
Darknet logo
Installation is simple and requires running just 3 lines of code (in order to use GPU it is necessary to modify the settings in the Makefile script after cloning the repository). For more details, see the Darknet installation instructions.
After installation, we can use a pre-trained model or build a new one from scratch. For example, here’s how you can detect objects on your image using a model pre-trained on the COCO dataset:
 YOLO output
YOLO output
As you can see in the image above, the algorithm deals well even with object representations.
 YOLO output (2)
If you want to see more, go to the Darknet website.
YOLO output (2)
If you want to see more, go to the Darknet website.
You don't have to build your Machine Learning model from scratch. In fact, it's usually better not to. Read our Introduction to Transfer Learning to find out why.This article was originally written by Michał Maj with further contributions from the Appsilon ML team.
Resources
- Need help with ML solutions? Reach out to Appsilon
- Ship recognition in satellite imagery
- Recognizing animals in photos
- Natural disaster relief assistance
- Identifying wildlife in the Serengeti
- Assisting biodiversity conservation efforts in Gabon
Follow Appsilon for More
- Appsilon is hiring! See open roles here.
- Follow @Appsilon on Twitter
- Follow Appsilon on LinkedIn
- Try out our R Shiny open source packages



.png)
